
The previous article gave some introduction to the networks used in deep learning. This article provides more information on the different types of neural networks.
In a feed-forward neural network (FFN) all the neurons in one layer are connected to the next layer. The advantage is that all the information processed from the previous neurons is fed to the next layer hence getting clarity in the process. But the number of weights and biases significantly increases when there is a large number of input. This method is best used for text data.
In a convolutional neural network (CNN), some of the neurons are only connected to the next layer i.e. connection is partial. Batch-wise information is fed into the next layer. The advantage is that the number of parameters significantly reduces when compared to FFN. This method is best used for image data since there will be thousands of inputs.
In recurrent neural networks, the output of one neuron is fed back as an input to the neuron in the previous layer. A feed-forward and a feedback connection are established between the neurons. The advantage is that the neuron in the previous layer can perform efficiently and can update based on the output from the next neuron. This concept is similar to reinforcement learning in the brain. The brain learns an action based on punishment or reward given as feedback to the neuron corresponding to that action.
Once the final output is computed by the network, it is then compared with the original value, and their difference is taken in different forms like the difference of squares, etc. this term is known as loss function.
It will be better to explain the role of the learning algorithms here. The learning algorithm is the one that tries to find the relation between the input and output. In the case of neural networks, the output is indirectly related to input since there are some hidden layers in between them. This learning algorithm works in such a way so as to find the optimum w and b values for the loss function is minimum or ideally zero.
The algorithm in neural networks do this using a method called backpropagation. In this method, the algorithm starts tracing from the output. It then computes the values for the parameters corresponding to the neuron in that layer. It then goes back to the previous layer does the computations for the parameters of the neurons in that layer. This procedure is done till it encounters the inputs. In this way, we can find the optimum values for the parameters.
The computations made by the algorithm are based on the type of the algorithm. Most of the algorithms find the derivative of a parameter in one layer with respect to the loss function using backpropagation. This derivative is then subtracted from the original value.
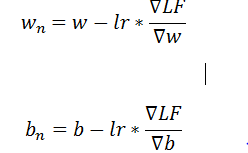
Where lr is the learning rate; provided by the user. The lesser the learning rate, the better will be the results but more the time is taken. The starting value for w and b is determined using the initialization.
| Method | Meaning |
| Zero | W and b are set to zero |
| Xavier | w and b indirectly proportional to root n |
| He | w and b indirectly proportional to root n/2 |
Where n; refers to the number of neurons in a layer. These depend on the activation function used.
The derivative of the loss function determines the updating of the parameters.
| Value of derivative | Consequence |
| -ve | Increases |
| 0 | No change |
| +ve | Decreases |
The derivative of the loss function with respect to the weight or bias in a particular layer can be determined using the chain rule used in calculus.

You must be logged in to post a comment.